Этапы Науки Данных: описание и применение моделей
Модели науки о данных — это вычислительные и математические структуры, которые позволяют извлекать идеи, закономерности и знания из сложных и часто больших наборов данных. Они охватывают широкий спектр методов, включая статистические методы, алгоритмы машинного обучения и архитектуры глубокого обучения. Эти модели предназначены для анализа и интерпретации данных, составления прогнозов и поддержки процессов принятия решений в различных областях. Преобразуя необработанные данные в применимые на практике интеллектуальные данные, модели науки о данных играют решающую роль в решении реальных проблем, оптимизации операций и стимулировании инноваций в таких отраслях, как финансы, здравоохранение, электронная коммерция и технологии.
Предлагаю описания и применимость наиболее распространенных моделей, которые дают обзор основных принципов каждой модели и того, как они функционируют. Они составляют основную часть инструментария науки о данных, позволяя практикам решать широкий спектр проблем, выбирая наиболее подходящую модель на основе конкретных требований и характеристик своих данных.
1. Модели контролируемого обучения
• Линейная регрессия
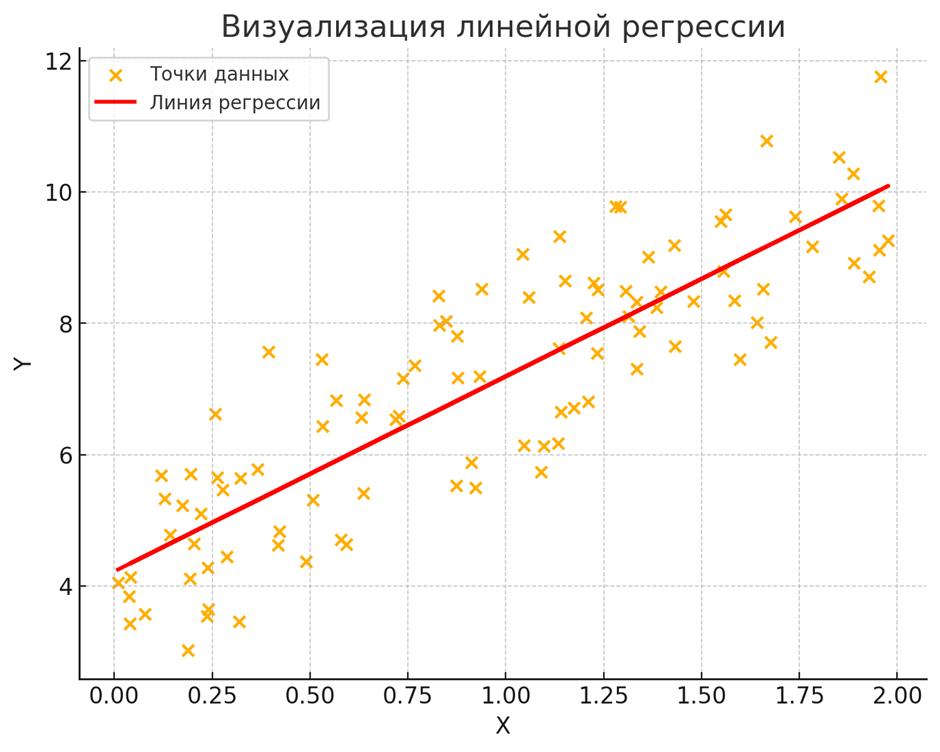
Линейная регрессия — это фундаментальный статистический метод, используемый для моделирования взаимосвязи между зависимой переменной и одной или несколькими независимыми переменными путем подгонки линейного уравнения к наблюдаемым данным. Он направлен на поиск наиболее подходящей прямой линии (известной как линия регрессии) через точки данных путем минимизации различий между наблюдаемыми значениями и значениями, предсказанными линейной функцией. Его простота и легкость интерпретации делают его широко используемым инструментом для прогнозирования непрерывных результатов в различных областях.
Линейная регрессия часто используется для прогнозирования непрерывных результатов, таких как прогнозы продаж, цены на жилье и цены акций. Его простота и интерпретируемость делают его подходящей моделью для задач регрессии. Кроме того, линейная регрессия используется в эконометрике для моделирования экономического роста, в науке об окружающей среде для прогнозирования уровней загрязняющих веществ и в здравоохранении для анализа взаимосвязи между факторами риска и результатами для здоровья. Она служит базовой моделью для многих задач прогнозирования и полезна для выявления и количественной оценки взаимосвязей между переменными.
• Логистическая регрессия
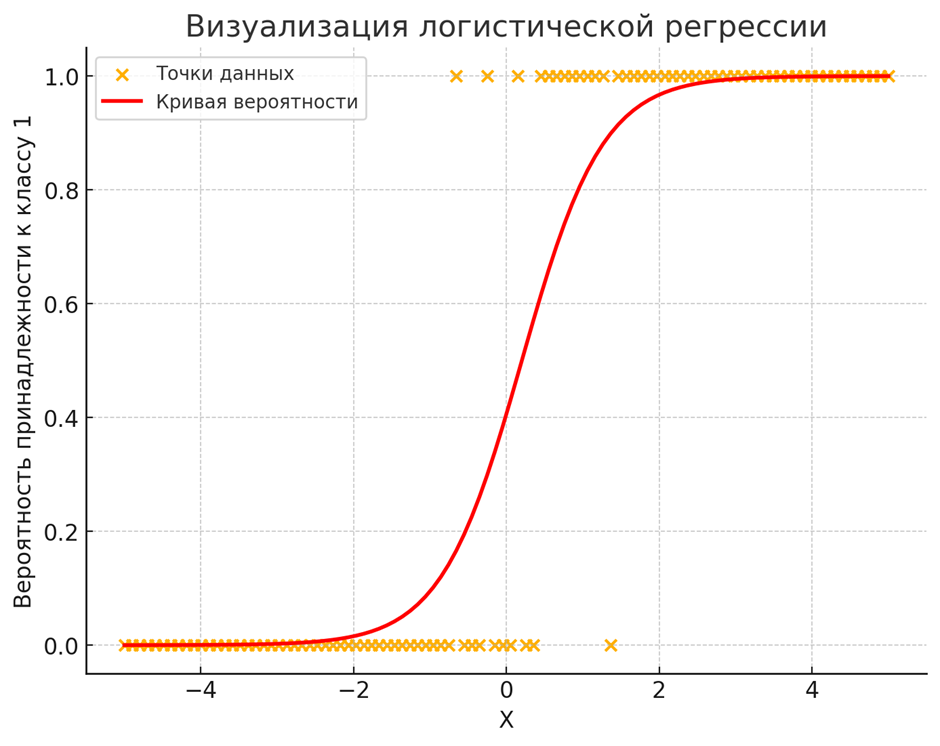
Логистическая регрессия — это алгоритм классификации, используемый для прогнозирования вероятности бинарного результата (да/нет, правда/ложь) на основе одной или нескольких переменных-предсказателей. Он использует логистическую функцию для моделирования бинарной зависимой переменной, преобразуя выходные данные в диапазон от 0 до 1. Эта модель оценивает связь между независимыми переменными и вероятностью конкретного результата, что делает ее ценной для оценки рисков и процессов принятия решений.
Основа для задач бинарной классификации, широко используется в финансах для кредитного скоринга, здравоохранении для прогнозирования заболеваний и маркетинге для анализа оттока клиентов. Логистическая регрессия также применяется в социальных науках для моделирования поведения, такого как модели голосования или принятие новых технологий. В эпидемиологии она используется для изучения связи между воздействием и результатами для здоровья, например, влияние курения на риск рака легких. Ее способность давать представление о влиянии переменных-предсказателей делает ее ценной для разработки политики и стратегического планирования.
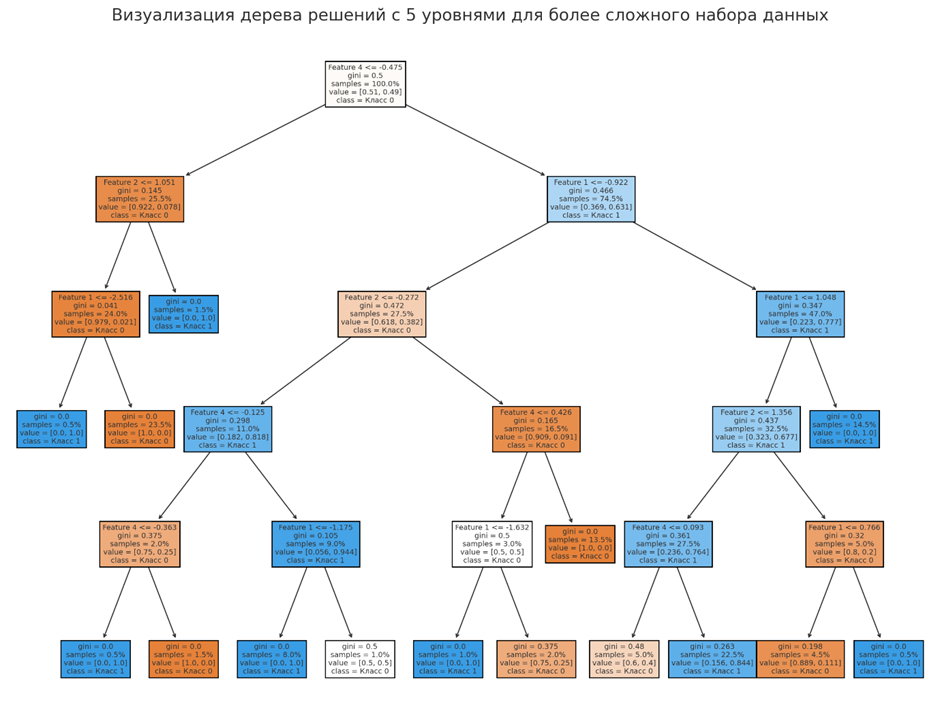
• Деревья решений и случайные леса
Деревья решений — это структуры, похожие на блок-схемы, которые рекурсивно разделяют набор данных на подмножества на основе значения входных признаков, что приводит к решению или прогнозу на листьях. Случайные леса улучшают эту концепцию, создавая ансамбль деревьев решений, объединяя их результаты для повышения точности прогнозирования и контроля переобучения. Объединяя несколько деревьев, случайные леса уменьшают дисперсию и повышают надежность, что делает их эффективными как для задач классификации, так и для задач регрессии.
Популярны как для классификации, так и для регрессии. Деревья решений просты в интерпретации, в то время как случайные леса повышают надежность за счет снижения переобучения и повышения точности. Распространены в таких отраслях, как здравоохранение для диагностики заболеваний, финансы для обнаружения мошенничества и оценки рисков, а также электронная коммерция для сегментации клиентов и систем рекомендаций. Они также используются в моделировании окружающей среды для прогнозирования таких явлений, как закономерности вырубки лесов, и в производстве для процессов контроля качества.
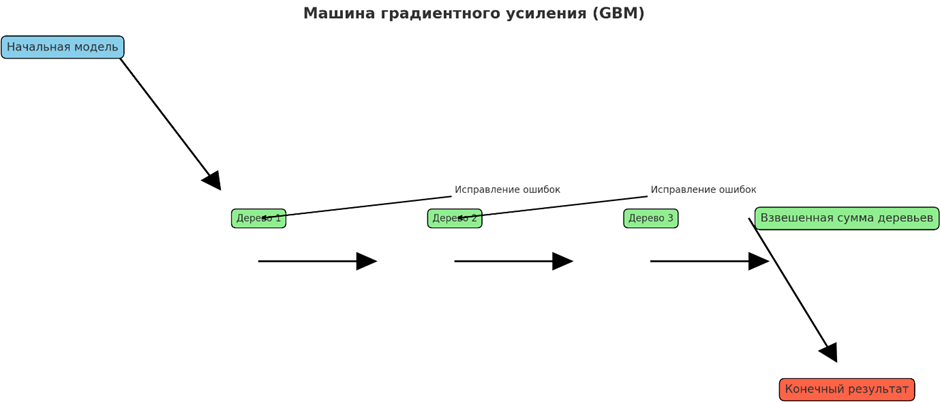
• Машины градиентного усиления (GBM), XGBoost, LightGBM
Это ансамблевые методы обучения, которые строят модели последовательно, где каждая новая модель фокусируется на исправлении ошибок предыдущих. Машины градиентного усиления оптимизируют модель, минимизируя указанную функцию потерь с помощью градиентного спуска. XGBoost и LightGBM — это передовые реализации, которые предлагают повышенную скорость и производительность с помощью таких методов, как обрезка деревьев, регуляризация и эффективная обработка разреженных данных, что делает их очень эффективными для сложных наборов данных.
Высокоэффективны для структурированных/табличных данных и фавориты в соревнованиях по машинному обучению. Они используются в кредитном скоринге для прогнозирования невыплат кредитов, предиктивном обслуживании для прогнозирования отказов оборудования и анализе рисков для оценки страховых требований. Такие отрасли, как финансы, страхование и здравоохранение, используют эти модели за их превосходную производительность и способность обрабатывать большие сложные наборы данных с пропущенными значениями и категориальными переменными.
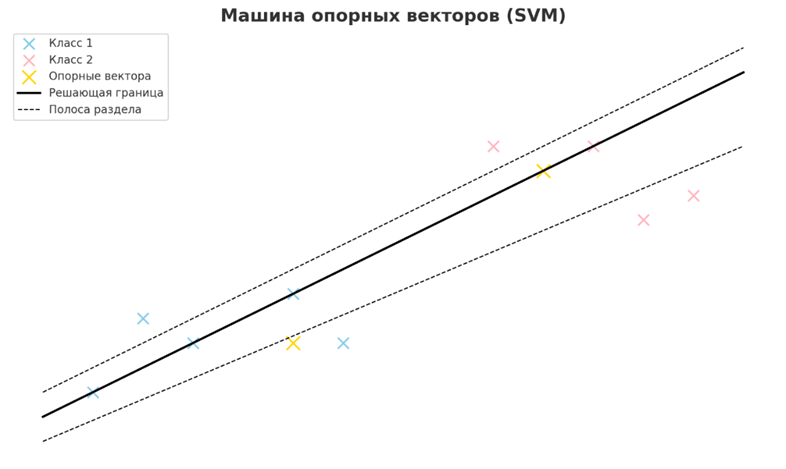
• Машины опорных векторов (SVM)
SVM — это контролируемый алгоритм обучения, используемый для задач классификации и регрессии, который работает путем поиска оптимальной гиперплоскости, которая наилучшим образом разделяет данные на разные классы. Он максимизирует разницу между ближайшими точками данных разных классов, известными как опорные векторы. SVM может эффективно обрабатывать линейные и нелинейные данные с помощью функций ядра, обеспечивая гибкость и надежность в многомерных пространствах.
Часто применяется в многомерных задачах классификации, таких как классификация изображений, категоризация текста и биоинформатика. В биоинформатике SVM используются для классификации белков, анализа экспрессии генов и прогнозирования заболеваний на основе генетических данных. В интеллектуальном анализе текста они эффективно справляются с обнаружением спама, анализом настроений и классификацией документов. SVM также используются в системах распознавания рукописного ввода, распознавания лиц и обнаружения вторжений из-за их способности управлять сложными шаблонами и нелинейными отношениями.
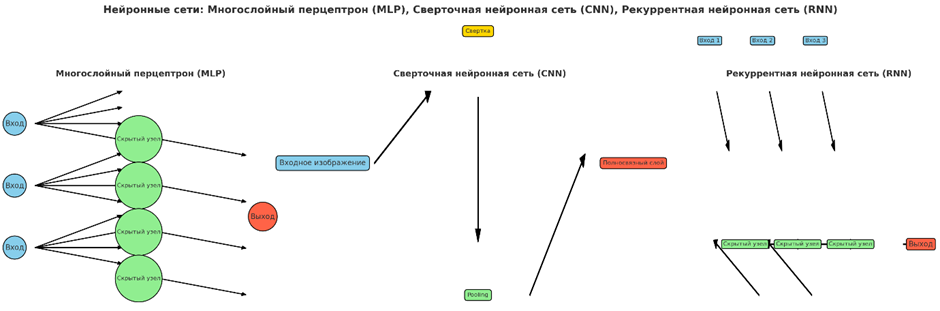
• Нейронные сети (MLP, CNN, RNN)
Нейронные сети — это вычислительные модели, вдохновленные человеческим мозгом, состоящие из слоев взаимосвязанных узлов (нейронов), которые обрабатывают данные путем регулировки весов связей. Многослойные персептроны (MLP) — это базовые нейронные сети, используемые для классификации и регрессии. Сверточные нейронные сети (CNN) специализируются на обработке данных в виде сетки, таких как изображения, используя сверточные слои для обнаружения закономерностей. Рекуррентные нейронные сети (RNN), включая LSTM, предназначены для последовательных данных, сохраняя информацию на временных шагах, что делает их подходящими для временных рядов и обработки языка.
Хотя нейронные сети более сложны, они очень эффективны в приложениях с большими объемами данных и сложными закономерностями. CNN широко используются в задачах обработки изображений, таких как обнаружение объектов, распознавание лиц и анализ медицинских изображений (например, обнаружение опухолей). RNN и LSTM широко используются в обработке естественного языка (NLP) и прогнозировании временных рядов, обеспечивая работу таких приложений, как языковой перевод, анализ настроений, распознавание речи, распознавание рукописного текста и прогнозирование фондового рынка.
2. Модели неконтролируемого обучения
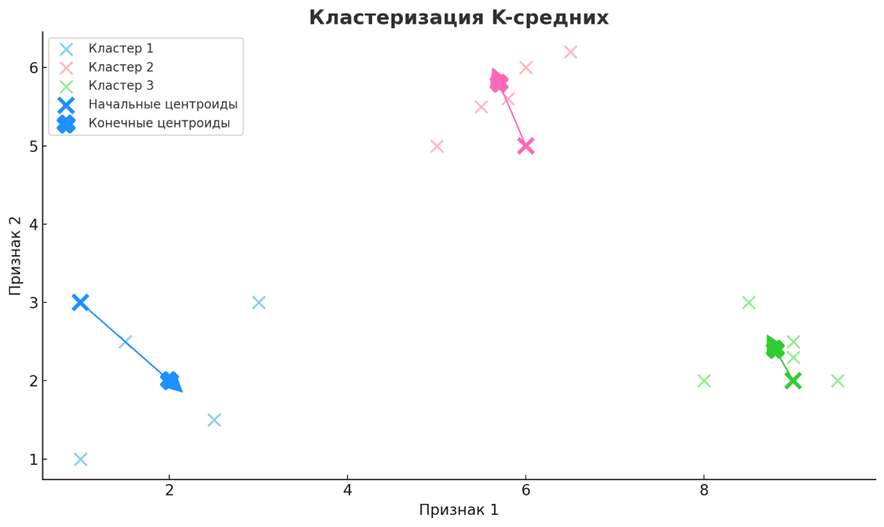
• Кластеризация K-средних
K-средние — это неконтролируемый алгоритм, который разбивает набор данных на K отдельных непересекающихся кластеров на основе сходства признаков. Он работает путем инициализации центроидов, назначения точек данных ближайшему центроиду, а затем пересчета центроидов как среднего значения назначенных точек. Этот итеративный процесс продолжается до тех пор, пока назначения кластеров не стабилизируются. K-средние ценятся за свою простоту и эффективность в определении присущих группировок в данных.
Один из наиболее распространенных методов кластеризации, особенно в сегментации рынка для определения отдельных групп клиентов на основе покупательского поведения, демографии или предпочтений. Он используется при сжатии изображений путем уменьшения количества цветов, в биологии для анализа экспрессии генов и в кластеризации документов для организации больших объемов текстовых данных. Его простота и масштабируемость делают его пригодным для исследовательского анализа и распознавания образов в различных отраслях.
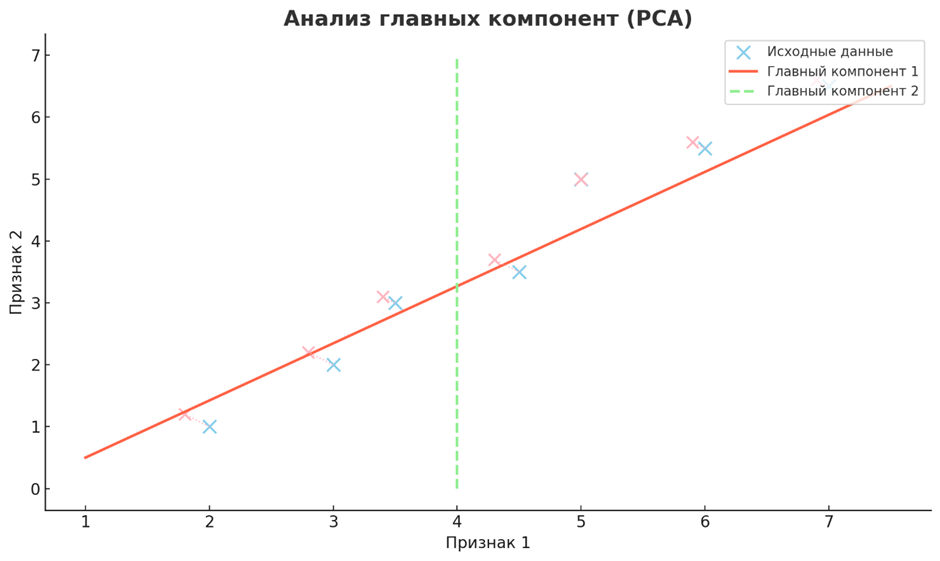
• Анализ главных компонент (PCA)
PCA — это метод снижения размерности, который преобразует высокоразмерные данные в форму с меньшей размерностью путем определения главных компонентов — ортогональных осей, которые фиксируют максимальную дисперсию в данных. Проецируя данные на эти оси, PCA снижает сложность, сохраняя основные закономерности, помогая в визуализации, снижении шума и извлечении признаков.
Широко используется для снижения размерности, извлечения признаков и визуализации данных. PCA необходим в исследовательском анализе данных для выявления базовых структур в данных, в сжатии изображений для сокращения пространства для хранения при сохранении качества изображения и в финансах для снижения размерности факторов риска портфеля. Он также используется в генетике для анализа структуры населения и в нейробиологии для обработки данных нейронных сигналов.
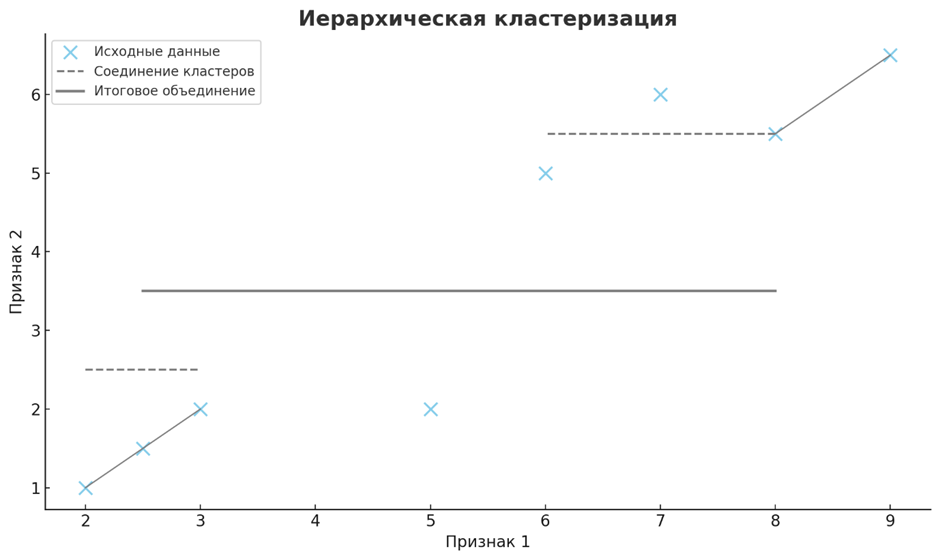
• Иерархическая кластеризация
Иерархическая кластеризация создает древовидную структуру (дендрограмму), представляющую вложенные группировки точек данных. Он может быть агломерационным (снизу вверх), начиная с отдельных точек данных и объединяя их в кластеры, или разделительным (сверху вниз), начиная с одного кластера и рекурсивно разделяя его. Этот метод особенно полезен, когда данные демонстрируют естественную иерархию или когда количество кластеров неизвестно.
Применяется в сегментации клиентов для понимания иерархических отношений между группами клиентов, в анализе социальных сетей для обнаружения структур сообществ и в генетических исследованиях для иллюстрации эволюционных отношений между видами или генами. Иерархическая кластеризация также используется в интеллектуальном анализе текста для организации документов в темы и подтемы и в экологии для классификации мест обитания на основе видового состава.
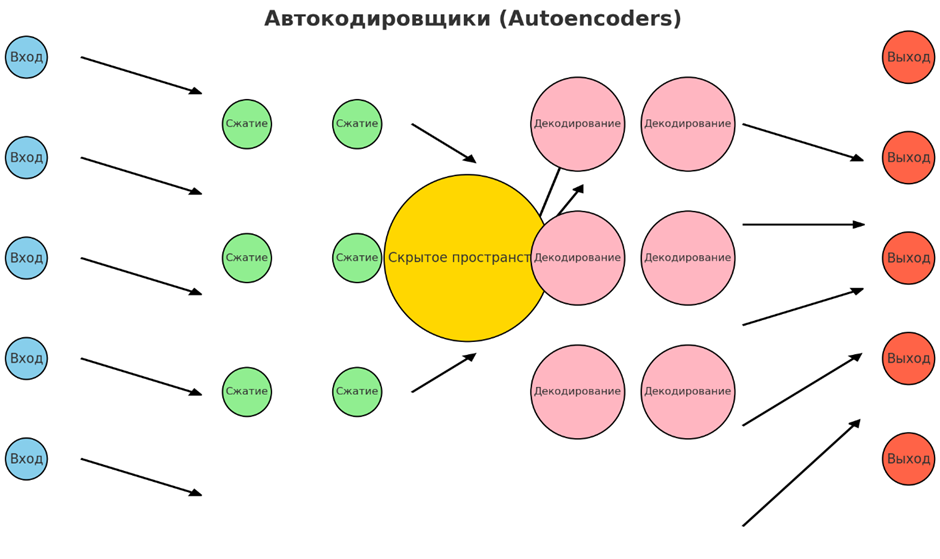
• Автокодировщики
Автокодировщики — это нейронные сети, разработанные для обучения эффективным кодировкам входных данных путем сжатия их в скрытое пространственное представление и последующей реконструкции. Они состоят из кодировщика, который отображает входные данные в пространство с меньшей размерностью, и декодера, который реконструирует исходные данные из этого представления. Автокодировщики используются для снижения размерности, обучения признакам и таких задач, как обнаружение аномалий, где ошибки реконструкции могут сигнализировать об отклонениях.
Обычно используются для обнаружения аномалий в кибербезопасности для выявления сетевых вторжений, в производстве для обнаружения дефектов в продуктах и в финансах для выявления мошеннических транзакций. Автокодировщики широко распространены в реконструкции изображений для шумоподавления изображений или дорисовки недостающих частей. Они также используются в системах рекомендаций для изучения скрытых признаков пользователей и предметов, улучшения персонализации и в здравоохранении для анализа сложных медицинских данных, таких как МРТ-сканы.
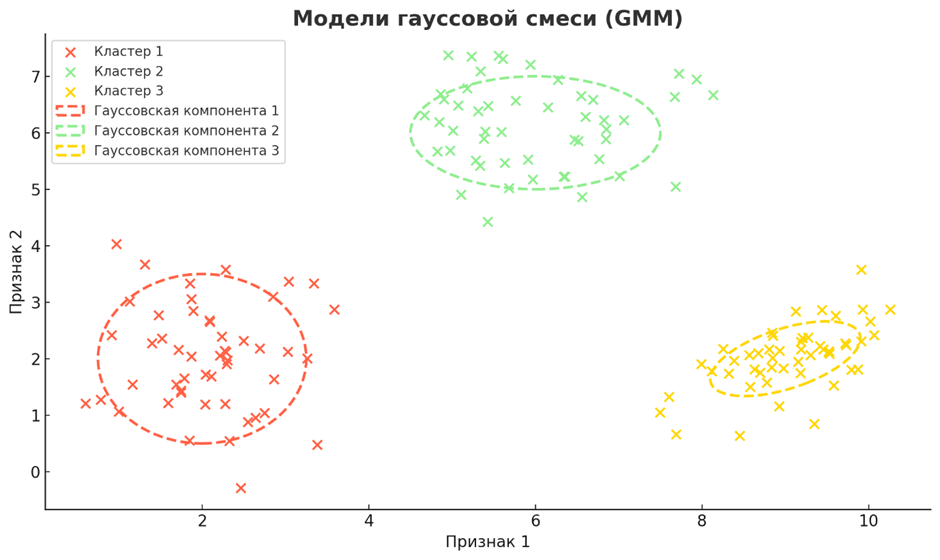
• Модели гауссовой смеси (GMM)
GMM — это вероятностные модели, которые предполагают, что все точки данных генерируются из смеси нескольких гауссовых распределений с неизвестными параметрами. Каждый компонент представляет собой кластер, а точкам данных назначаются вероятности принадлежности к каждому кластеру. GMM гибки в моделировании данных с субпопуляциями и способны захватывать сложные формы кластеров и перекрывающиеся кластеры.
Используется в таких приложениях, как распознавание говорящего для моделирования характеристик голосового тракта, сегментация изображений для различения различных объектов или регионов и оценка плотности, где понимание распределения данных имеет решающее значение. В финансах GMM моделируют доходность активов для оптимизации портфеля. Они также используются в астрофизике для классификации небесных объектов и в маркетинге для определения сегментов клиентов с перекрывающимися характеристиками.
3. Рекомендательные системы
• Совместная фильтрация
Совместная фильтрация предсказывает интересы пользователя, собирая предпочтения многих пользователей. Она работает на основе предположения, что пользователи, которые согласились в прошлом, склонны соглашаться и в будущем. Этот метод анализирует взаимодействие пользователя с товарами, чтобы рекомендовать товары на основе сходства между пользователями (на основе пользователя) или товарами (на основе товара), что делает его краеугольным камнем в персонализированных рекомендательных системах.
Основа рекомендательных систем в потоковых сервисах, таких как Netflix и Spotify, предлагающая фильмы или песни на основе оценок пользователей и привычек прослушивания. На платформах электронной коммерции, таких как Amazon, она рекомендует товары, анализируя историю покупок и шаблоны просмотра. Платформы социальных сетей используют совместную фильтрацию для персонализации каналов контента и предложения новых связей. Она очень эффективна для улучшения взаимодействия пользователей и стимулирования продаж за счет персонализированного опыта.

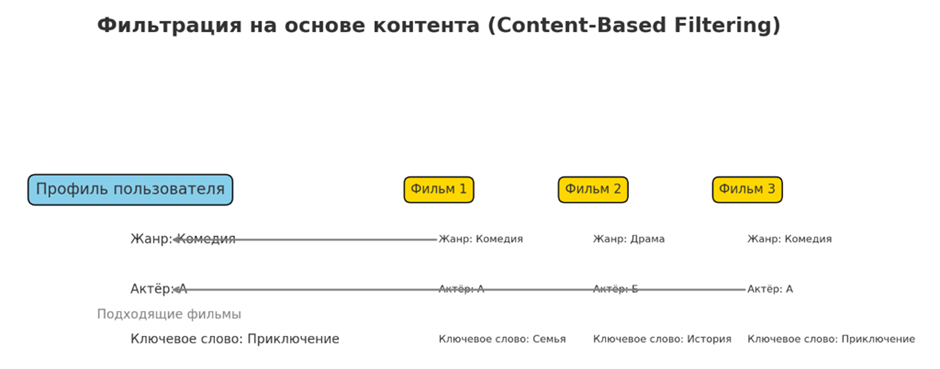
• Фильтрация на основе контента
Фильтрация на основе контента рекомендует товары пользователю, сравнивая содержимое товаров и прошлые предпочтения пользователя. Он создает профиль пользователя на основе характеристик элемента (таких как ключевые слова, категории или атрибуты), с которыми взаимодействовал пользователь, и предлагает новые элементы, которые соответствуют этому профилю. Этот метод особенно эффективен, когда доступны подробные метаданные элемента.
Часто используется на платформах, где атрибуты контента четко определены, например, новостные агрегаторы, рекомендующие статьи на основе тем или ключевых слов, к которым проявил интерес пользователь. В музыкальных потоковых сервисах он предлагает новые песни или исполнителей, похожие по жанру, темпу или стилю на то, что нравится пользователю. Фильтрация на основе контента также применяется на порталах вакансий для рекомендации должностей, соответствующих навыкам и опыту кандидата, и в академических базах данных для предложения соответствующих исследовательских работ.
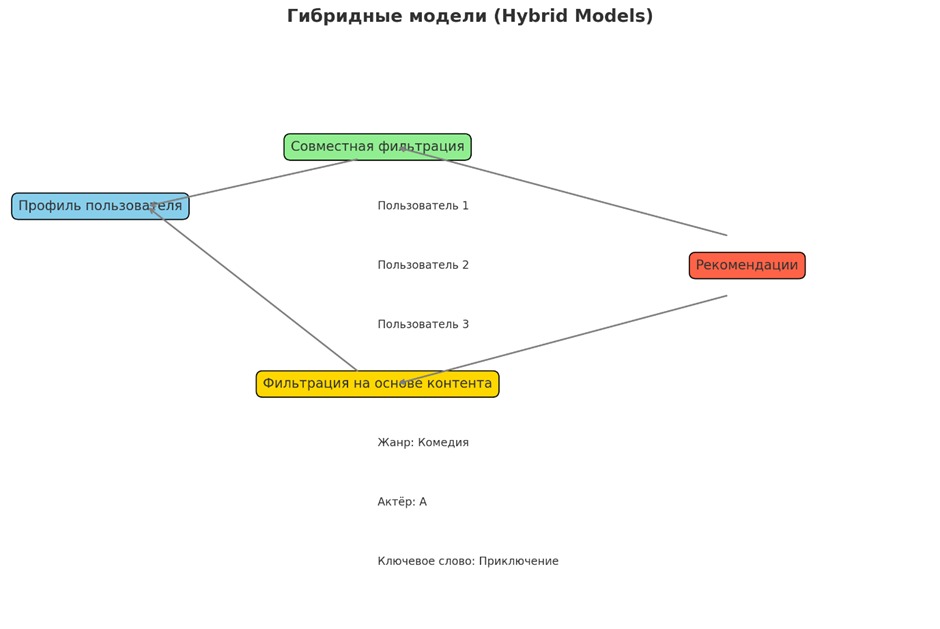
• Гибридные модели
Гибридные рекомендательные системы объединяют методы совместной и контентной фильтрации, чтобы использовать сильные стороны обоих и смягчать их слабые стороны. Интегрируя несколько алгоритмов, гибридные модели могут повысить точность рекомендаций, более эффективно обрабатывать новых пользователей или элементы и предоставлять более широкий спектр предложений, улучшая общий пользовательский опыт.
Широко применяется в сложных сценариях рекомендаций для повышения точности. Например, Amazon использует гибридные модели для рекомендации продуктов, объединяя историю покупок пользователей со сходством предметов. Netflix использует их для предложения фильмов, учитывая как привычки просмотра, так и атрибуты контента, такие как жанр и актерский состав. Гибридные модели также используются в интернет-рекламе для показа персонализированной рекламы путем анализа поведения пользователей и контента рекламы, максимизируя показатели вовлеченности и конверсии.
4. Модели глубокого обучения
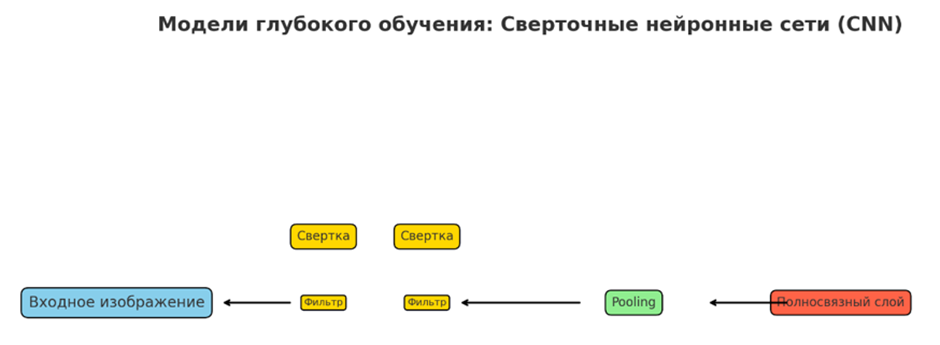
• Сверточные нейронные сети (CNN)
CNN — это специализированные нейронные сети, предназначенные для обработки данных с топологией, похожей на сетку, например, изображений. Они используют сверточные слои для автоматического и адаптивного изучения пространственных иерархий признаков с помощью обратного распространения, применяя фильтры к локальным областям входных данных. Слои объединения уменьшают размерность, а полностью связанные слои выводят окончательный прогноз. CNN отлично справляются с захватом пространственных и временных зависимостей в данных.
Необходимы для задач обработки изображений и видео, таких как обнаружение объектов, распознавание лиц и медицинская диагностика изображений, например, обнаружение опухолей при МРТ-сканировании. CNN также используются в автономных транспортных средствах для интерпретации визуальных данных для обнаружения препятствий и дорожных знаков, в сельском хозяйстве для мониторинга урожая и скота, а также в приложениях дополненной реальности для картирования окружающей среды и наложения объектов. Они преобразили компьютерное зрение и обеспечили значительные достижения в областях, требующих анализа изображений.
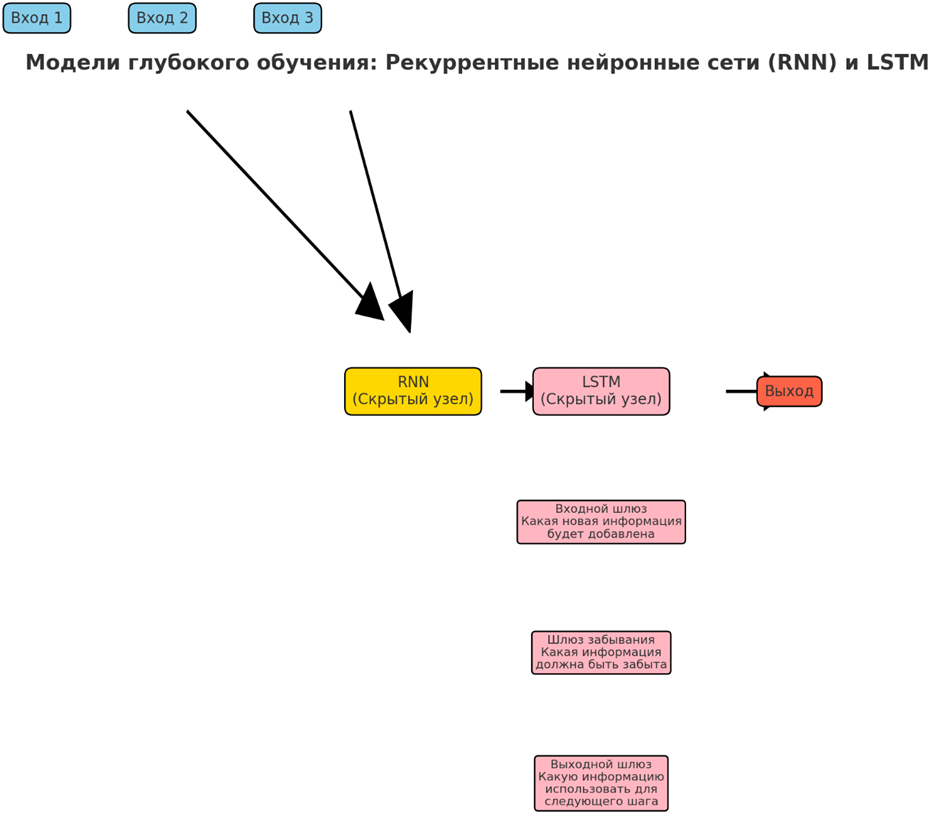
• Рекуррентные нейронные сети (RNN) и LSTM
RNN — это нейронные сети с циклами, которые позволяют информации сохраняться, что делает их идеальными для последовательных данных. Они обрабатывают входные данные последовательно, сохраняя скрытое состояние, которое фиксирует контекст. Однако стандартные RNN борются с долгосрочными зависимостями из-за проблемы исчезающего градиента. Сети с долговременной краткосрочной памятью (LSTM) решают эту проблему, включая шлюзы, которые регулируют поток информации, позволяя сети обучаться на более длинных последовательностях.
Эффективные для последовательных данных, RNN и LSTM популярны в приложениях NLP, включая языковой перевод, где они преобразуют текст с одного языка на другой; анализ настроений, определяющий эмоциональный тон слов; и распознавание речи, транскрибируя произнесенные слова в текст. Они также используются в прогнозировании временных рядов для цен акций, прогнозировании погоды и в здравоохранении для мониторинга пациентов с течением времени. Их способность моделировать временные зависимости делает их бесценными в любой области, связанной с последовательными данными.
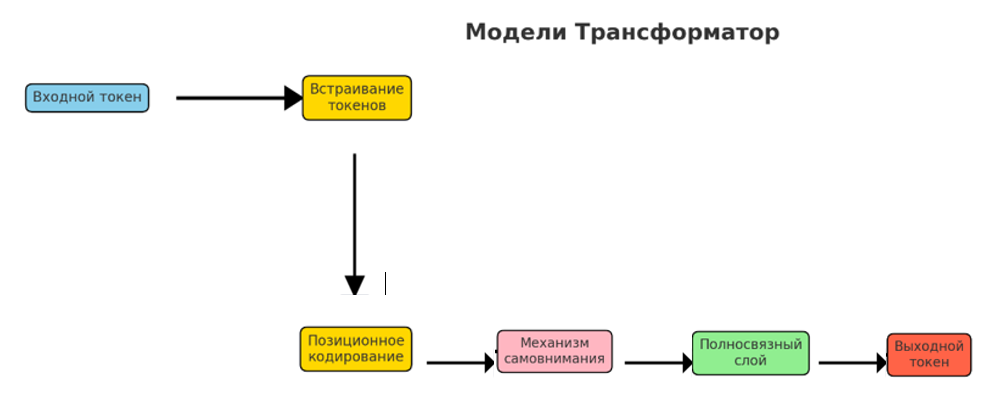
• Модели Трансформатор
Модел Трансформатор — это тип архитектуры нейронной сети, которая полностью полагается на механизмы внутреннего внимания для параллельной обработки последовательностей, а не последовательно, как в RNN. Это обеспечивает большую эффективность и возможность улавливать долгосрочные зависимости. Такие модели, как BERT (представления двунаправленного кодировщика из Transformer) и GPT (генеративный предварительно обученный Transformer), достигли самых современных результатов в различных задачах обработки естественного языка благодаря своей способности понимать контекст и генерировать связный текст.
Такие модели, как BERT и GPT, являются самыми современными для задач обработки естественного языка. Transformer произвели революцию в машинном переводе, обеспечив более точные и плавные переводы. Они широко используются в виртуальных помощниках, таких как Siri и Alexa, для понимания и генерации ответов на естественном языке. Transformer питают чат-ботов в обслуживании клиентов, автоматизируют резюмирование текста в новостных и юридических документах, помогают в создании контента путем генерации статей или кода и улучшают поисковые системы за счет лучшего понимания запросов и ранжирования результатов.
5. Временные ряды и модели прогнозирования
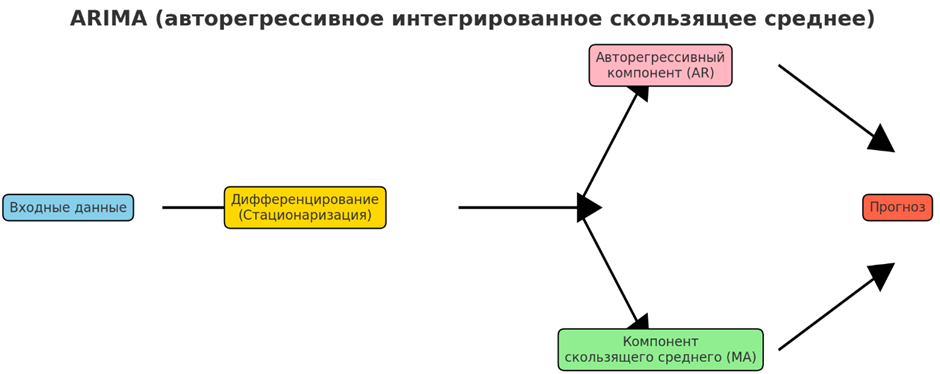
• ARIMA (авторегрессивное интегрированное скользящее среднее)
ARIMA — это статистическая модель, используемая для анализа и прогнозирования данных временных рядов. Она объединяет авторегрессионные термины (зависимость от предыдущих значений), дифференцирование (для достижения стационарности) и скользящие средние остатков. Модели ARIMA особенно эффективны для одномерного прогнозирования временных рядов, где необходимо уловить такие закономерности, как тенденции и сезонность.
Часто используются для прогнозирования временных рядов на финансовых рынках для прогнозирования цен акций, обменных курсов или экономических показателей. В розничной торговле модели ARIMA прогнозируют продажи для управления запасами и уровнями персонала. Коммунальные службы используют их для прогнозирования нагрузки, чтобы предвидеть спрос на электроэнергию или воду. В науке об окружающей среде они помогают прогнозировать погодные условия, уровни загрязнения и другие экологические явления. Их статистическая основа делает их надежными для краткосрочного и среднесрочного прогнозирования, где исторические закономерности являются информативными.
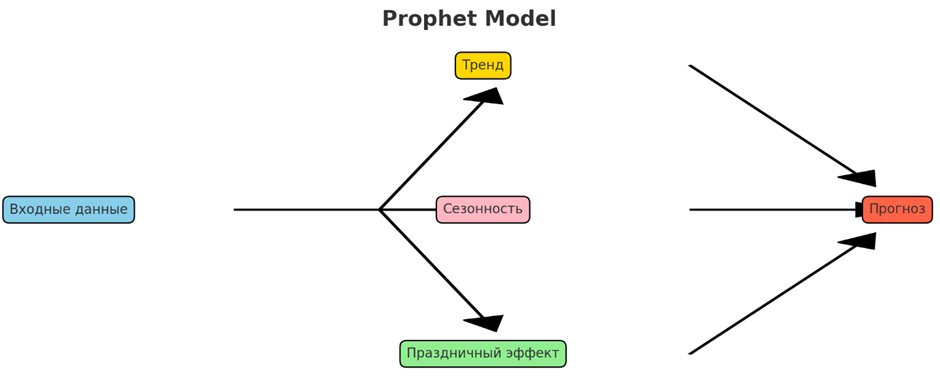
• Prophet
Prophet — это инструмент прогнозирования с открытым исходным кодом, разработанный Facebook, предназначенный для обработки данных временных рядов с множественными сезонностями и тенденциями. Он использует аддитивную модель, в которой нелинейные тренды соответствуют ежегодным, еженедельным и ежедневным сезонным компонентам, а также эффектам праздников. Prophet удобен для пользователя, требует минимальной подготовки данных и настройки параметров, что делает его доступным для приложений бизнес-аналитики.
Надежная модель, разработанная Facebook для прогнозирования временных рядов, полезная для обработки отсутствующих данных и сезонных тенденций. Популярна в бизнес-аналитике для прогнозирования продаж, трафика веб-сайта или показателей вовлеченности пользователей. Используется в логистике для прогнозирования объемов отгрузок, в финансах для бюджетирования и финансового планирования, а в маркетинге для прогнозирования эффективности кампаний. Простота использования делает ее подходящей для аналитиков и предприятий без глубоких знаний в моделировании временных рядов.
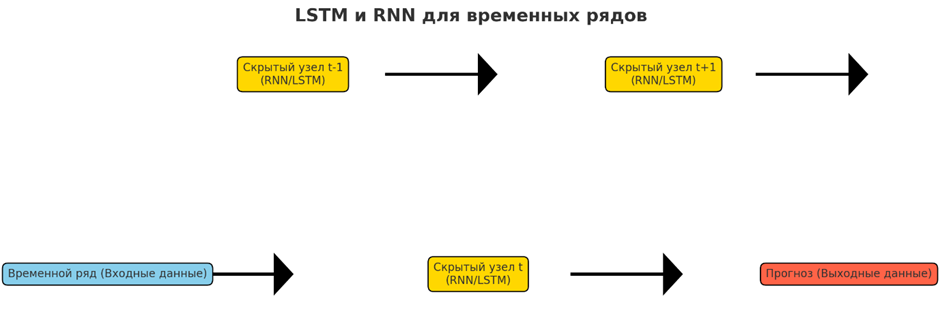
• LSTM и RNN
Как упоминалось ранее, LSTM и RNN хорошо подходят для моделирования последовательных и временных данных благодаря своей способности сохранять информацию на протяжении временных шагов. В прогнозировании временных рядов они могут улавливать сложные закономерности и зависимости, которые могут упускать традиционные модели, такие как нелинейные тенденции и меняющиеся сезонные эффекты.
Применяется для решения сложных задач временных рядов, где критически важны долгосрочные зависимости. В финансах они прогнозируют цены акций и рыночные тенденции. В энергетике они прогнозируют уровни потребления и производства для оптимизации распределения ресурсов. Модели прогнозирования погоды используют LSTM для прогнозирования изменений температуры, осадков и экстремальных явлений. Они также используются в здравоохранении для прогнозирования состояния пациентов путем анализа жизненно важных показателей с течением времени и в профилактическом обслуживании для прогнозирования отказов оборудования до того, как они произойдут.
6. Модели оптимизации и принятия решений
• Линейное программирование (ЛП)
Линейное программирование — это математический метод определения наилучшего результата в модели, требования которой представлены линейными отношениями. Оно включает оптимизацию линейной целевой функции с учетом ограничений линейного равенства и неравенства. ЛП широко используется для распределения ресурсов, планирования производства, составления расписаний и решения транспортных задач, где целью является максимизация эффективности или минимизация затрат.
Широко используемые в исследованиях операций, модели ЛП оптимизируют распределение ресурсов в производстве для определения оптимального состава продуктов, в транспортной логистике для минимизации расходов на доставку и времени доставки, а также в планировании рабочей силы для эффективного распределения персонала. В сельском хозяйстве ЛП помогает в планировании урожая для максимизации прибыли или урожайности с учетом ограничений по земле, рабочей силе и воде. Оно также используется при составлении рациона для скота для минимизации затрат при удовлетворении потребностей в питании.
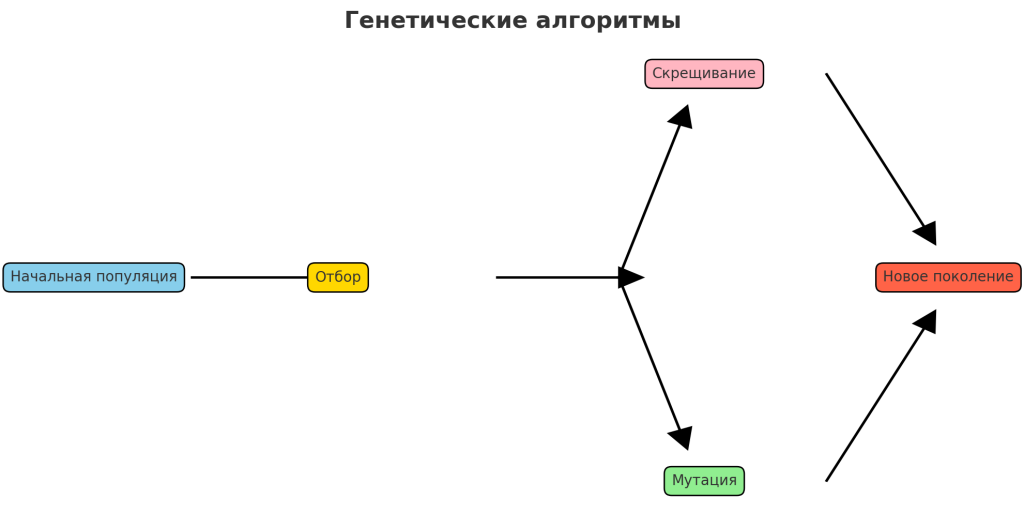
• Генетические алгоритмы
Генетические алгоритмы — это поисковые эвристики, вдохновленные процессом естественного отбора. Они генерируют решения для задач оптимизации и поиска путем итеративного выбора, комбинирования и мутации возможных решений, руководствуясь функцией приспособленности. Генетические алгоритмы полезны для сложных задач с большими, мультимодальными или плохо понятными пространствами поиска, такими как инженерное проектирование и планирование.
Используются для задач оптимизации с большими пространствами решений. В инженерном проектировании они оптимизируют конструкции, такие как мосты и компоненты самолетов, по весу и прочности. В планировании они создают эффективные расписания для школ или мастерских. Генетические алгоритмы используются в машинном обучении для настройки гиперпараметров с целью повышения производительности моделей. В телекоммуникациях они оптимизируют конфигурации сетей, а в биоинформатике они помогают в выравнивании последовательностей ДНК и моделировании сворачивания белков.
• Марковские процессы принятия решений (MDP)
MDP предоставляют математическую основу для моделирования ситуаций принятия решений, где результаты частично случайны и частично находятся под контролем лица, принимающего решения. Они характеризуются состояниями, действиями, вероятностями перехода и вознаграждениями. MDP имеют основополагающее значение в обучении с подкреплением, позволяя разрабатывать оптимальные политики для последовательных задач принятия решений в таких областях, как робототехника, автономные системы и теория игр.
Применяются в обучении с подкреплением для задач принятия решений. В робототехнике MDP помогают в планировании пути и задачах навигации. Автономные системы вождения используют их для принятия решений в режиме реального времени в условиях неопределенности. В исследовании операций они оптимизируют управление запасами и системы очередей. MDP также используются в экономике для моделирования поведения потребителей и в здравоохранении для планирования лечения, когда ответы пациентов неопределенны.
7. Модели обнаружения аномалий
• Леса изоляции
Леса изоляции — это метод обнаружения аномалий на основе ансамбля, который изолирует аномалии вместо профилирования обычных точек данных. Благодаря построению случайных деревьев решений, которые разделяют точки данных, аномалии, которых немного и которые отличаются друг от друга, быстро изолируются, что приводит к сокращению длины пути. Этот метод эффективен, масштабируем и эффективен для обнаружения выбросов в многомерных наборах данных.
Популярен для выявления аномалий в наборах данных. В обнаружении мошенничества они раскрывают необычные шаблоны транзакций. В кибербезопасности леса изоляции обнаруживают сетевые вторжения и вредоносные действия. Промышленные системы мониторинга используют их для выявления неисправностей оборудования путем выявления отклонений от нормальных рабочих данных. Они также применяются в здравоохранении для выявления аномальных показателей жизнедеятельности пациентов и в финансах для выявления нерегулярных рыночных действий.
• Одноклассовые SVM
Одноклассовые опорные векторные машины — это неконтролируемые алгоритмы, которые изучают границу принятия решений вокруг нормальных данных, позволяя обнаруживать новые или аномальные точки данных, которые выходят за эти границы. Они особенно полезны, когда доступны только примеры нормального поведения, что делает их подходящими для таких приложений, как контроль качества и обнаружение неисправностей.
Подходят для обнаружения новинок, часто используются в контроле качества для выявления дефектных продуктов в производственных процессах. В сетевой безопасности они обнаруживают необычный сетевой трафик, который может указывать на кибератаки. В здравоохранении одноклассовые SVM помогают выявлять аномальные данные пациентов, указывающие на медицинские состояния. Они также используются в мониторинге окружающей среды для обнаружения необычных закономерностей в климатических данных и в финансах для выявления мошеннических транзакций.
• Автокодировщики (для обнаружения аномалий)
При обнаружении аномалий автокодировщики обучаются восстанавливать входные данные, изучая сжатое представление нормальных закономерностей. Аномалии, которые отличаются от нормальных данных, приводят к более высоким ошибкам реконструкции. Установив пороговое значение этой ошибки, модель может отмечать аномалии, что делает автокодировщики эффективными для таких задач, как обнаружение мошенничества, обнаружение вторжений и мониторинг сложных систем.
Эффективны для обнаружения аномалий путем изучения сжатого представления обычных данных. Применяются для обнаружения неисправностей для мониторинга машин и оборудования в производстве, прогнозирования сбоев до их возникновения. В кибербезопасности автокодировщики обнаруживают аномалии в сетевом трафике, которые могут указывать на нарушения безопасности. В здравоохранении они отслеживают данные пациентов для обнаружения нарушений в частоте сердечных сокращений или других жизненно важных показателях. Автокодировщики также используются в финансах для выявления необычных закономерностей в торговых данных, которые могут указывать на манипулирование рынком.
Эти модели стали основным инструментом для науки о данных, обеспечивая решения в различных областях, таких как финансы, здравоохранение, электронная коммерция и социальные сети. Выбор модели зависит от конкретной проблемы, доступности данных и требований к производительности, но приведенные выше модели постоянно используются из-за их эффективности и адаптивности.